
April 25, 2024


Tech

New AI method captures uncertainty in medical images
By providing plausible label maps for one medical image, the Tyche machine-learning model could…
MIT engineers design soft and flexible “skeletons” for muscle-powered robots
New modular, spring-like devices maximize the work of live muscle fibers so they can be harnessed to power biohybrid bots.…
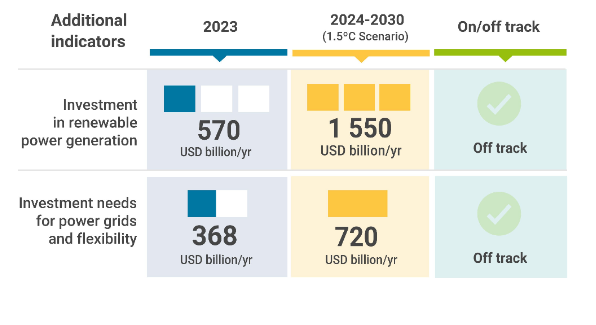
COP28 Goal of Tripling Renewables Feasible Only with Urgent Global Course Correction
Abu Dhabi, UAE – Achieving the global target set at COP28 to triple renewable power capacity by 2030 relies heavily…
Researchers enhance peripheral vision in AI models
CAMBRIDGE, Mass. — Peripheral vision enables humans to see shapes that aren’t directly in our line of sight, albeit with…
Research
Education
Japan(RS)— Osaka Metropolitan University researcher demonstrates that social and educational indicators strongly affect the…

The University of Wisconsin–Madison formally installed Chancellor Jennifer L. Mnookin as its 30th leader…

Doha— Bangladesh’s Minister for Education says her government plans to enrol 650,000 children into…
Health



Fitness
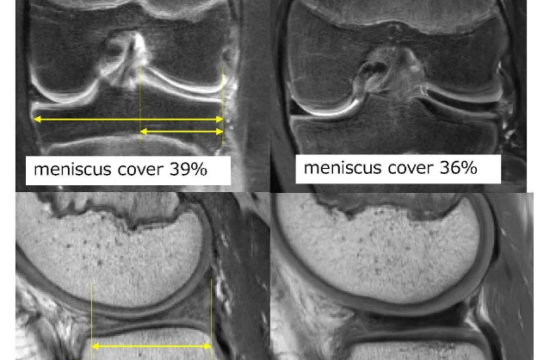
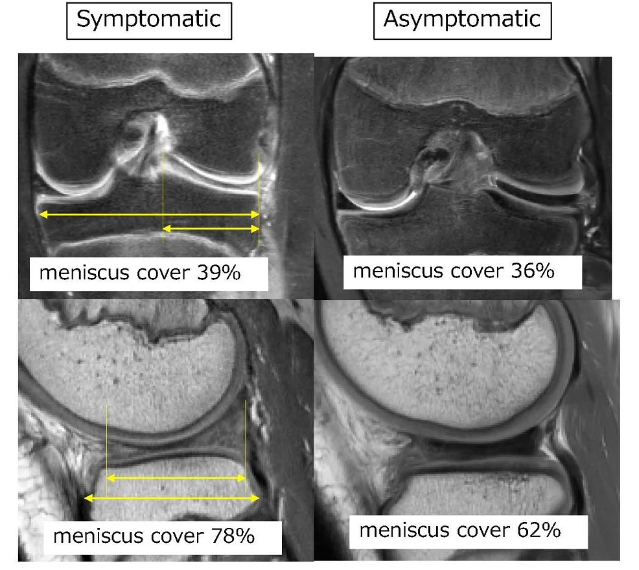
MRI Comparisons of the symptomatic and asymptomatic groups: Results showed that coronal and sagittal occupancy rates ...

Researchers at Tohoku University have developed a new smart chair that may solve office workers’ back ...

Sleeping safe and sound is one of human’s most fundamental needs to stay re-energized and maintain ...

Miki Kamatani The Covid-19 pandemic has improved perceptions of facial attractiveness and healthiness of people wearing ...
Competing at the highest level in college sports while managing a full class schedule and generally ...

[caption id="attachment_13541" align="alignnone" width="775"] Yoga instructor Paul Mross, who taught yoga for the new study, leads ...



Space/Astrophysics

VIENNA, WIS. – It was a balmy spring day in May 2009 when Jim Koch's plow ...

NASA astronaut Loral O'Hara returned to Earth after a six-month research mission aboard the International Space Station on ...

A study by MIT physicists suggest the Milky Way’s gravitational core may be lighter in mass, ...


NASA has selected 72 student teams to begin an engineering design challenge to build human-powered rovers ...


Osaka, Japan - Showers in bathrooms bring us comfort; showers from space bring astrophysicists joy. Osaka ...

Chandrayaan-3 is the first space mission to touch down near the Moon's south pole, according to ...


Culture

Kailasanatha Temple: A Largest Monolithic Rock-Cut Monument In the World
Kailasanatha Temple, the temple was declared a UNESCO World Heritage Site in 1983 as part of the Ellora Caves complex. It is also known as the Kailasa and Cave 16, the Kailasanatha temple at Ellora is the largest monolithic rock-cut monument in the world. At 32 metres high and 78 metres long, it is widely considered remarkable for its size, architecture and sculptural treatment. The temple is unusual in that…

SUTD Faculty Named Among World’s Most Cited Researchers in 2022
Professor Chua Chee Kai and Associate Professor Yuen Chau, from the Engineering Product Development (EPD) pillar at the Singapore University of Technology and Design (SUTD), are listed as Highly Cited Researchers™ (HCR)…

An International Biotech-Conference ‘BEST’ will be organized in Kathmandu
Kathmandu– Biotechnology for Environmental and Sustainable Technology (BEST), an international conference will be organized by the Biotechnology Society of Nepal (BSN) on 17-19 December 2022 in Kathmandu. According to BSN,…
Deadline Extended for Holographic Himalaya
Kathmandu— Holographic Himalaya has opened a call for applications from Bachelor and Master levels from Nepal with a background in theoretical physics and willing to commit for the period of…